| pugixml 0.9 manual | Overview | Installation | Document: Object model · Loading · Accessing · Modifying · Saving | XPath | API Reference | Table of Contents |
|
pugixml stores XML data in DOM-like way: the entire XML document (both document structure and element data) is stored in memory as a tree. The tree can be loaded from character stream (file, string, C++ I/O stream), then traversed via special API or XPath expressions. The whole tree is mutable: both node structure and node/attribute data can be changed at any time. Finally, the result of document transformations can be saved to a character stream (file, C++ I/O stream or custom transport).
The XML document is represented with a tree data structure. The root of the
tree is the document itself, which corresponds to C++ type xml_document. Document has one or more
child nodes, which correspond to C++ type xml_node.
Nodes have different types; depending on a type, a node can have a collection
of child nodes, a collection of attributes, which correspond to C++ type
xml_attribute, and some additional
data (i.e. name).
The tree nodes can be of one of the following types (which together form
the enumeration xml_node_type):
node_document) - this
is the root of the tree, which consists of several child nodes. This
node corresponds to xml_document
class; note that xml_document
is a sub-class of xml_node,
so the entire node interface is also available. However, document node
is special in several ways, which will be covered below. There can be
only one document node in the tree; document node does not have any XML
representation. node_element) - this
is the most common type of node, which represents XML elements. Element
nodes have a name, a collection of attributes and a collection of child
nodes (both of which may be empty). The attribute is a simple name/value
pair. The example XML representation of element node is as follows:
<node attr="value"><child/></node>
There are two element nodes here; one has name
"node", single attribute"attr"and single child"child", another has name"child"and does not have any attributes or child nodes.
node_pcdata)
represent plain text in XML. PCDATA nodes have a value, but do not have
name or children/attributes. Note that plain character data is not a
part of the element node but instead has its own node; for example, an
element node can have several child PCDATA nodes. The example XML representation
of text node is as follows:
<node> text1 <child/> text2 </node>
Here
"node"element has three children, two of which are PCDATA nodes with values"text1"and"text2".
<node> <![CDATA[[text1]]> <child/> <![CDATA[[text2]]> </node>
CDATA nodes make it easy to include non-escaped <, & and > characters in plain text. CDATA value can not contain the character sequence ]]>, since it is used to determine the end of node contents.
<!-- comment text -->
Here the comment node has value
"comment text". By default comment nodes are treated as non-essential part of XML markup and are not loaded during XML parsing. You can override this behavior by addingparse_commentsflag.
<?name value?>
Here the name (also called PI target) is
"name", and the value is"value". By default PI nodes are treated as non-essential part of XML markup and are not loaded during XML parsing. You can override this behavior by addingparse_piflag.
node_declaration)
represents document declarations in XML. Declaration nodes have a name
("xml") and an
optional collection of attributes, but does not have value or children.
There can be only one declaration node in a document; moreover, it should
be the topmost node (its parent should be the document). The example
XML representation of declaration node is as follows:
<?xml version="1.0"?>
Here the node has name
"xml"and a single attribute with name"version"and value"1.0". By default declaration nodes are treated as non-essential part of XML markup and are not loaded during XML parsing. You can override this behavior by addingparse_declarationflag. Also, by default a dummy declaration is output when XML document is saved unless there is already a declaration in the document; you can disable this by addingformat_no_declarationflag.
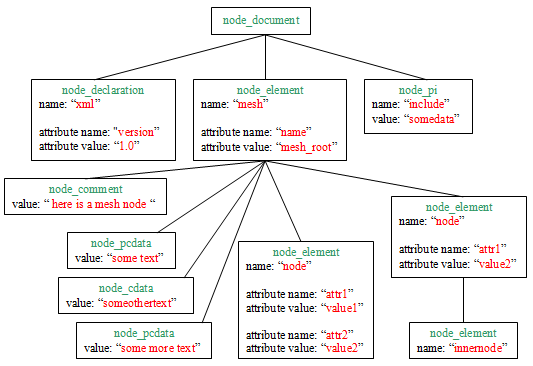
Finally, here is a complete example of XML document and the corresponding tree representation (samples/tree.xml):
|
<?xml version="1.0"?> <mesh name="mesh_root"> <!-- here is a mesh node --> some text <![CDATA[someothertext]]> some more text <node attr1="value1" attr2="value2" /> <node attr1="value2"> <innernode/> </node> </mesh> <?include somedata?>
|
|
![[Note]](../images/note.png) |
Note |
|---|---|
All pugixml classes and functions are located in |
Despite the fact that there are several node types, there are only three
C++ types representing the tree (xml_document,
xml_node, xml_attribute);
some operations on xml_node
are only valid for certain node types. They are described below.
xml_document is the owner
of the entire document structure; it is a non-copyable class. The interface
of xml_document consists
of loading functions (see Loading document), saving functions (see Saving document)
and the interface of xml_node,
which allows for document inspection and/or modification. Note that while
xml_document is a sub-class
of xml_node, xml_node is not a polymorphic type; the
inheritance is only used to simplify usage.
Default constructor of xml_document
initializes the document to the tree with only a root node (document node).
You can then populate it with data using either tree modification functions
or loading functions; all loading functions destroy the previous tree with
all occupied memory, which puts existing nodes/attributes from this document
to invalid state. Destructor of xml_document
also destroys the tree, thus the lifetime of the document object should exceed
the lifetimes of any node/attribute handles that point to the tree.
![[Caution]](../images/caution.png) |
Caution |
|---|---|
While technically node/attribute handles can be alive when the tree they're referring to is destroyed, calling any member function of these handles results in undefined behavior. Thus it is recommended to make sure that the document is destroyed only after all references to its nodes/attributes are destroyed. |
xml_node is the handle to
document node; it can point to any node in the document, including document
itself. There is a common interface for nodes of all types; the actual node
type can be queried via xml_node::type() method. Note that xml_node
is only a handle to the actual node, not the node itself - you can have several
xml_node handles pointing
to the same underlying object. Destroying xml_node
handle does not destroy the node and does not remove it from the tree. The
size of xml_node is equal
to that of a pointer, so it is nothing more than a lightweight wrapper around
pointer; you can safely pass or return xml_node
objects by value without additional overhead.
There is a special value of xml_node
type, known as null node or empty node (such nodes have type node_null). It does not correspond to any
node in any document, and thus resembles null pointer. However, all operations
are defined on empty nodes; generally the operations don't do anything and
return empty nodes/attributes or empty strings as their result (see documentation
for specific functions for more detailed information). This is useful for
chaining calls; i.e. you can get the grandparent of a node like so: node.parent().parent(); if a node is a null node or it does not
have a parent, the first parent() call returns null node; the second parent()
call then also returns null node, so you don't have to check for errors twice.
xml_attribute is the handle
to an XML attribute; it has the same semantics as xml_node,
i.e. there can be several xml_attribute
handles pointing to the same underlying object, there is a special null attribute
value, which propagates to function results.
Both xml_node and xml_attribute have the default constructor
which initializes them to null objects.
xml_node and xml_attribute try to behave like pointers,
that is, they can be compared with other objects of the same type, making
it possible to use them as keys of associative containers. All handles to
the same underlying object are equal, and any two handles to different underlying
objects are not equal. Null handles only compare as equal to themselves.
The result of relational comparison can not be reliably determined from the
order of nodes in file or other ways. Do not use relational comparison operators
except for search optimization (i.e. associative container keys).
Additionally handles they can be implicitly cast to boolean-like objects,
so that you can test if the node/attribute is empty by just doing if (node) { ...
} or if
(!node) { ...
} else { ... }.
Alternatively you can check if a given xml_node/xml_attribute handle is null by calling
the following methods:
bool xml_attribute::empty() const; bool xml_node::empty() const;
Nodes and attributes do not exist outside of document tree, so you can't
create them without adding them to some document. Once underlying node/attribute
objects are destroyed, the handles to those objects become invalid. While
this means that destruction of the entire tree invalidates all node/attribute
handles, it also means that destroying a subtree (by calling remove_child) or removing an attribute
invalidates the corresponding handles. There is no way to check handle validity;
you have to ensure correctness through external mechanisms.
There are two choices of interface and internal representation when configuring
pugixml: you can either choose the UTF-8 (also called char) interface or
UTF-16/32 (also called wchar_t) one. The choice is controlled via PUGIXML_WCHAR_MODE define; you can set
it via pugiconfig.hpp or via preprocessor options, as discussed in Additional configuration
options.
If this define is set, the wchar_t interface is used; otherwise (by default)
the char interface is used. The exact wide character encoding is assumed
to be either UTF-16 or UTF-32 and is determined based on size of wchar_t type.
|
Note |
|---|---|
If size of |
All tree functions that work with strings work with either C-style null terminated strings or STL strings of the selected character type. For example, node name accessors look like this in char mode:
const char* xml_node::name() const; bool xml_node::set_name(const char* value);
and like this in wchar_t mode:
const wchar_t* xml_node::name() const; bool xml_node::set_name(const wchar_t* value);
There is a special type, pugi::char_t,
that is defined as the character type and depends on the library configuration;
it will be also used in the documentation hereafter. There is also a type
pugi::string_t, which is defined as the STL string
of the character type; it corresponds to std::string
in char mode and to std::wstring in wchar_t mode.
In addition to the interface, the internal implementation changes to store
XML data as pugi::char_t; this means that these two modes
have different memory usage characteristics. The conversion to pugi::char_t upon document loading and from
pugi::char_t upon document saving happen automatically,
which also carries minor performance penalty. The general advice however
is to select the character mode based on usage scenario, i.e. if UTF-8 is
inconvenient to process and most of your XML data is localized, wchar_t mode
is probably a better choice.
There are cases when you'll have to convert string data between UTF-8 and wchar_t encodings; the following helper functions are provided for such purposes:
std::string as_utf8(const wchar_t* str); std::wstring as_wide(const char* str);
Both functions accept null-terminated string as an argument str, and return the converted string.
as_utf8 performs conversion
from UTF-16/32 to UTF-8; as_wide
performs conversion from UTF-8 to UTF-16/32. Invalid UTF sequences are silently
discarded upon conversion. str
has to be a valid string; passing null pointer results in undefined behavior.
|
Note |
|---|---|
|
Most examples in this documentation assume char interface and therefore
will not compile with
you'll have to do
|
Almost all functions in pugixml have the following thread-safety guarantees:
Concurrent modification and traversing of a single tree requires synchronization, for example via reader-writer lock. Modification includes altering document structure and altering individual node/attribute data, i.e. changing names/values.
The only exception is set_memory_management_functions;
it modifies global variables and as such is not thread-safe. Its usage policy
has more restrictions, see Custom memory allocation/deallocation
functions.
With the exception of XPath, pugixml itself does not throw any exceptions. Additionally, most pugixml functions have a no-throw exception guarantee.
This is not applicable to functions that operate on STL strings or IOstreams;
such functions have either strong guarantee (functions that operate on strings)
or basic guarantee (functions that operate on streams). Also functions that
call user-defined callbacks (i.e. xml_node::traverse
or xml_node::find_node) do not provide any exception
guarantees beyond the ones provided by callback.
XPath functions may throw xpath_exception
on parsing error; also, XPath implementation uses STL, and thus may throw
i.e. std::bad_alloc in low memory conditions. Still,
XPath functions provide strong exception guarantee.
pugixml requests the memory needed for document storage in big chunks, and allocates document data inside those chunks. This section discusses replacing functions used for chunk allocation and internal memory management implementation.
All memory for tree structure/data is allocated via globally specified functions, which default to malloc/free. You can set your own allocation functions with set_memory_management functions. The function interfaces are the same as that of malloc/free:
typedef void* (*allocation_function)(size_t size); typedef void (*deallocation_function)(void* ptr);
You can use the following accessor functions to change or get current memory management functions:
void set_memory_management_functions(allocation_function allocate, deallocation_function deallocate); allocation_function get_memory_allocation_function(); deallocation_function get_memory_deallocation_function();
Allocation function is called with the size (in bytes) as an argument and should return a pointer to memory block with alignment that is suitable for pointer storage and size that is greater or equal to the requested one. If the allocation fails, the function has to return null pointer (throwing an exception from allocation function results in undefined behavior). Deallocation function is called with the pointer that was returned by the previous call or with a null pointer; null pointer deallocation should be handled as a no-op. If memory management functions are not thread-safe, library thread safety is not guaranteed.
This is a simple example of custom memory management (samples/custom_memory_management.cpp):
void* custom_allocate(size_t size) { return new (std::nothrow) char[size]; } void custom_deallocate(void* ptr) { delete[] static_cast<char*>(ptr); }
pugi::set_memory_management_functions(custom_allocate, custom_deallocate);
When setting new memory management functions, care must be taken to make sure that there are no live pugixml objects. Otherwise when the objects are destroyed, the new deallocation function will be called with the memory obtained by the old allocation function, resulting in undefined behavior.
|
Note |
|---|---|
Currently memory for XPath objects is allocated using default operators new/delete; this will change in the next version. |
Constructing a document object using the default constructor does not result
in any allocations; document node is stored inside the xml_document
object.
When the document is loaded from file/buffer, unless an inplace loading
function is used (see Loading document from memory), a complete copy of character
stream is made; all names/values of nodes and attributes are allocated
in this buffer. This buffer is allocated via a single large allocation
and is only freed when document memory is reclaimed (i.e. if the xml_document object is destroyed or if
another document is loaded in the same object). Also when loading from
file or stream, an additional large allocation may be performed if encoding
conversion is required; a temporary buffer is allocated, and it is freed
before load function returns.
All additional memory, such as memory for document structure (node/attribute objects) and memory for node/attribute names/values is allocated in pages on the order of 32 kilobytes; actual objects are allocated inside the pages using a memory management scheme optimized for fast allocation/deallocation of many small objects. Because of the scheme specifics, the pages are only destroyed if all objects inside them are destroyed; also, generally destroying an object does not mean that subsequent object creation will reuse the same memory. This means that it is possible to devise a usage scheme which will lead to higher memory usage than expected; one example is adding a lot of nodes, and them removing all even numbered ones; not a single page is reclaimed in the process. However this is an example specifically crafted to produce unsatisfying behavior; in all practical usage scenarios the memory consumption is less than that of a general-purpose allocator because allocation meta-data is very small in size.
| pugixml 0.9 manual | Overview | Installation | Document: Object model · Loading · Accessing · Modifying · Saving | XPath | API Reference | Table of Contents |
|